Hashing Table
Hash Table: Hash table is a method/mechanism of finding a record in a table/list using a key. Suppose we have n record and m key values where m >= n then it for every key if there exist a record n then it a hash table where m is a hash key.
Hash key: Hash key is a unique number which can be converted to a record in a record in a hash table. Here there is a mapping function h(m) which maps each hash key to corresponding records. This function is called hash function.
Hash function: Hash function is a mapping function of hash table which takes the key number as input and gives out the index of the record.
n = h(m) (where m >=n)
Here is a very simple hash function like mod. Suppose we have maximum 10 records. Then we can easily map key to index of record n by mod(m). It directly gives us the record number.
n = mod 10 (m)
In a perfect hash table where m >=n there is always record index for a key. When m > n then more than one key may map to a same record. This situation is called hash collision.
Hash collision: If more than one hash key can be mapped to a single record in a hash table then it is called has collision. Example: Say in our example key values ranges from 0 to 9. If we take 10 or more as key then say key m=1 corresponds to record n=1. Now key m=11 also maps to the same record as mod10(11)=1.
There are three popular techniques to avoid collision
- Linear probing,
- Chaining,
- Re-hashing
Linear probing
In linear probing records are placed to the next neighborhood of the colliding record.
Chaining
Chaining is the technique to remap colliding record to a new linked list chain.
Re-hashing
Re-hashing is the second level of hash table with these new colliding records.
Binary Tree
A binary tree is a method of placing and locating files (called records or keys) in a database, especially when all the data is known to be in random access memory (RAM). The algorithm finds data by repeatedly dividing the number of ultimately accessible records in half until only one remains.
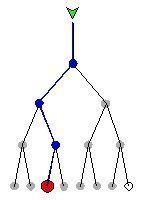
In a tree, records are stored in locations called leaves. This name derives from the fact that records always exist at end points; there is nothing beyond them. Branch points are called nodes. The order of a tree is the number of branches (called children) per node. In a binary tree, there are always two children per node, so the order is 2. The number of leaves in a binary tree is always a power of 2. The number of access operations required to reach the desired record is called the depth of the tree. The image to the left shows a binary tree for locating a particular record among seven records in a set of eight leaves. The depth of this tree is 4.
In a practical tree, there can be thousands, millions, or billions of records. Not all leaves necessarily contain a record, but more than half do. A leaf that does not contain a record is called a null. In the example shown here, the eighth leaf is a null, indicated by an open circle.
Binary trees are used when all the data is in random-access memory (RAM). The search algorithm is simple, but it does not minimize the number of database accesses required to reach a desired record. When the entire tree is contained in RAM, which is a fast-read, fast-write medium, the number of required accesses is of little concern. But when some or all of the data is on disk, which is slow-read, slow-write, it is advantageous to minimize the number of accesses (the tree depth). Alternative algorithms such as the
B-tree accomplish this.